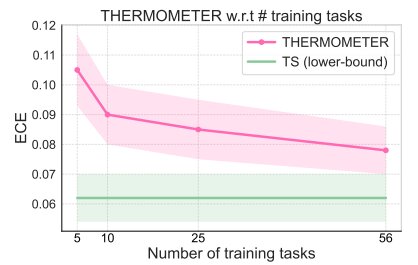
Performances du thermomètre par rapport au nombre de tâches d’entraînement. Les performances d’étalonnage du thermomètre (ECE moyen sur cinquante-sept tâches MMLU) s’améliorent à mesure que le nombre d’ensembles de données d’entraînement augmente. La zone ombrée représente deux erreurs standard. Crédit : arXiv (2024). DOI : 10.48550/arxiv.2403.08819
Les modèles linguistiques de grande taille sont utilisés pour un large éventail de tâches, de la traduction d’un article à l’identification d’une fraude financière. Cependant, malgré les capacités et la polyvalence incroyables de ces modèles, ils génèrent parfois des réponses inexactes.
En plus de ce problème, les modèles peuvent être trop confiants quant aux mauvaises réponses ou pas assez confiants quant aux bonnes réponses, ce qui rend difficile pour un utilisateur de savoir quand un modèle est fiable.
Les chercheurs calibrent généralement un modèle d’apprentissage automatique pour s’assurer que son niveau de confiance correspond à sa précision. Un modèle bien calibré devrait avoir moins confiance en une prédiction incorrecte, et vice-versa. Mais comme les grands modèles linguistiques (LLM) peuvent être appliqués à une collection apparemment infinie de tâches diverses, les méthodes d’étalonnage traditionnelles sont inefficaces.
Des chercheurs du MIT et du MIT-IBM Watson AI Lab ont mis au point une méthode d’étalonnage adaptée aux grands modèles linguistiques. Leur méthode, appelée « Thermometer », consiste à créer un modèle auxiliaire plus petit qui s’exécute sur un grand modèle linguistique pour l’étalonner.
Le thermomètre est plus efficace que d’autres approches, nécessitant moins de calculs gourmands en énergie, tout en préservant la précision du modèle et en lui permettant de produire des réponses mieux calibrées sur des tâches qu’il n’a jamais vues auparavant.
En permettant un étalonnage efficace d’un LLM pour une variété de tâches, Thermometer pourrait aider les utilisateurs à identifier les situations dans lesquelles un modèle est trop confiant quant aux fausses prédictions, les empêchant finalement de déployer ce modèle dans une situation où il pourrait échouer.
« Avec Thermomètre, nous voulons fournir à l’utilisateur un signal clair pour lui dire si la réponse d’un modèle est exacte ou inexacte, d’une manière qui reflète l’incertitude du modèle, afin qu’il sache si ce modèle est fiable », explique Maohao Shen, étudiant diplômé en génie électrique et informatique (EECS) et auteur principal d’un article sur Thermomètre.
Shen est rejoint sur le papier par Gregory Wornell, professeur d’ingénierie Sumitomo qui dirige le laboratoire des signaux, de l’information et des algorithmes au sein du laboratoire de recherche en électronique et est membre du MIT-IBM Watson AI Lab ; l’auteur principal Soumya Ghosh, membre du personnel de recherche du MIT-IBM Watson AI Lab ; ainsi que d’autres personnes au MIT et au MIT-IBM Watson AI Lab.
La recherche a récemment été présentée à la Conférence internationale sur l’apprentissage automatique (ICML 2024) qui s’est tenue à Vienne, en Autriche, du 21 au 27 juillet. Elle est disponible sur le site arXiv serveur de préimpression.
Calibrage universel
Les modèles d’apprentissage automatique traditionnels étant généralement conçus pour effectuer une seule tâche, leur étalonnage implique généralement une méthode spécifique à la tâche. D’un autre côté, comme les modèles LLM ont la flexibilité d’effectuer de nombreuses tâches, l’utilisation d’une méthode traditionnelle pour étalonner ce modèle pour une tâche donnée peut nuire à ses performances sur une autre tâche.
L’étalonnage d’un LLM implique souvent de prélever plusieurs fois des échantillons du modèle pour obtenir différentes prédictions, puis de les agréger pour obtenir une confiance mieux calibrée. Cependant, comme ces modèles comportent des milliards de paramètres, les coûts de calcul de telles approches s’accumulent rapidement.
« Dans un sens, les grands modèles de langage sont universels car ils peuvent gérer diverses tâches. Nous avons donc besoin d’une méthode d’étalonnage universelle qui puisse également gérer de nombreuses tâches différentes », explique Shen.
Avec le thermomètre, les chercheurs ont développé une technique polyvalente qui exploite une méthode d’étalonnage classique appelée mise à l’échelle de température pour étalonner efficacement un LLM pour une nouvelle tâche.
Dans ce contexte, une « température » est un paramètre d’échelle utilisé pour ajuster la confiance d’un modèle afin qu’elle soit alignée sur sa précision de prédiction. Traditionnellement, on détermine la bonne température à l’aide d’un ensemble de données de validation étiquetées d’exemples spécifiques à une tâche.
Les LLM étant souvent appliqués à de nouvelles tâches, il peut être presque impossible d’acquérir des ensembles de données étiquetés. Par exemple, un utilisateur qui souhaite déployer un LLM pour répondre aux questions des clients sur un nouveau produit ne dispose probablement pas d’un ensemble de données contenant de telles questions et réponses.
Au lieu d’utiliser un ensemble de données étiqueté, les chercheurs forment un modèle auxiliaire qui s’exécute sur un LLM pour prédire automatiquement la température nécessaire pour l’étalonner pour cette nouvelle tâche.
Ils utilisent des ensembles de données étiquetés de quelques tâches représentatives pour former le modèle Thermomètre, mais une fois celui-ci formé, il peut se généraliser à de nouvelles tâches dans une catégorie similaire sans avoir besoin de données étiquetées supplémentaires.
Un modèle de thermomètre formé sur une collection d’ensembles de données de questions à choix multiples, comprenant peut-être un ensemble de questions d’algèbre et un ensemble de questions médicales, pourrait être utilisé pour calibrer un LLM qui répondra à des questions sur la géométrie ou la biologie, par exemple.
« L’objectif est que cela fonctionne sur n’importe quelle tâche, mais nous n’y sommes pas encore tout à fait », explique Ghosh.
Le modèle Thermomètre n’a besoin d’accéder qu’à une petite partie du fonctionnement interne du LLM pour prédire la bonne température qui calibrera sa prédiction pour les points de données d’une tâche spécifique.
Une approche efficace
Il est important de noter que cette technique ne nécessite pas plusieurs cycles d’entraînement et ne ralentit que légèrement le LLM. De plus, comme la mise à l’échelle de la température ne modifie pas les prévisions d’un modèle, le thermomètre préserve sa précision.
Lorsqu’ils ont comparé le thermomètre à plusieurs lignes de base sur plusieurs tâches, il a systématiquement produit des mesures d’incertitude mieux calibrées tout en nécessitant beaucoup moins de calculs.
« Tant que nous formons un modèle de thermomètre sur un nombre suffisamment grand de tâches, il devrait être capable de bien se généraliser à n’importe quelle nouvelle tâche, tout comme un grand modèle de langage, c’est aussi un modèle universel », ajoute Shen.
Les chercheurs ont également découvert que s’ils formaient un modèle de thermomètre pour un LLM plus petit, il pouvait être directement appliqué pour calibrer un LLM plus grand au sein de la même famille.
À l’avenir, ils souhaitent adapter le modèle de thermomètre à des tâches de génération de texte plus complexes et appliquer la technique à des LLM encore plus volumineux. Les chercheurs espèrent également quantifier la diversité et le nombre d’ensembles de données étiquetés dont on aurait besoin pour former un modèle de thermomètre afin qu’il puisse être généralisé à une nouvelle tâche.
Plus d’information:
Maohao Shen et al., Thermomètre : vers un étalonnage universel pour les grands modèles linguistiques, arXiv (2024). DOI : 10.48550/arxiv.2403.08819
arXiv
Fourni par le Massachusetts Institute of Technology
Cet article est republié avec l’aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l’actualité de la recherche, de l’innovation et de l’enseignement au MIT.
Citation:La technique du « thermomètre » empêche un modèle d’IA d’être trop confiant quant aux mauvaises réponses (31 juillet 2024) récupéré le 31 juillet 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.