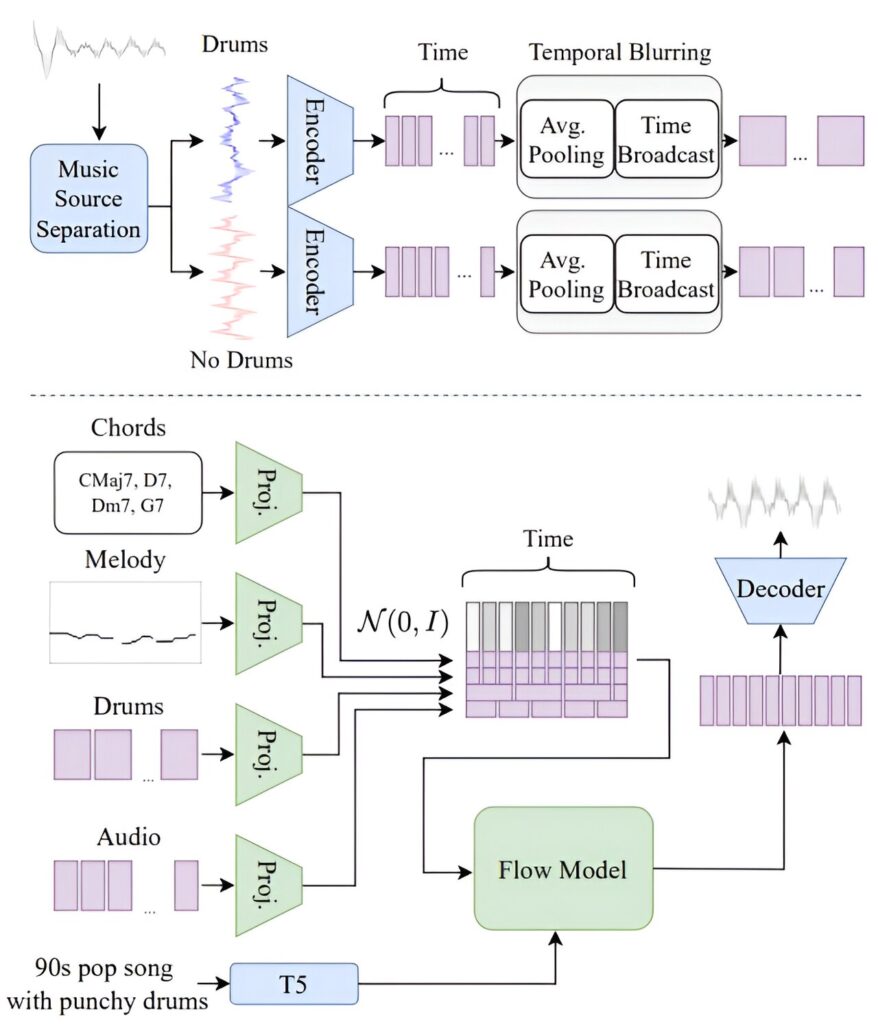
La figure du haut présente le processus de flou temporel, mettant en valeur la séparation des sources, la mise en commun et la diffusion. La figure du bas présente une présentation de haut niveau de JASCO. Les conditions sont d’abord projetées sur une représentation à faible dimension et sont concaténées sur les dimensions du canal. Les blocs verts ont des paramètres pouvant être appris tandis que les blocs bleus sont gelés. Crédit : arXiv (2024). DOI: 10.48550/arxiv.2406.10970
Une équipe de chercheurs en IA de l’équipe de recherche fondamentale en IA de Meta met à disposition du public quatre nouveaux modèles d’IA destinés aux chercheurs et aux développeurs qui créent de nouvelles applications. L’équipe a publié un article sur le site arXiv serveur de préimpression décrivant l’un des nouveaux modèles, JASCO, et comment il pourrait être utilisé.
L’intérêt pour les applications d’IA grandissant, les principaux acteurs du secteur créent des modèles d’IA qui peuvent être utilisés par d’autres entités pour ajouter des fonctionnalités d’IA à leurs propres applications. Dans le cadre de ce nouvel effort, l’équipe de Meta a mis à disposition quatre nouveaux modèles : JASCO, AudioSeal et deux versions de Chameleon.
JASCO a été conçu pour accepter différents types d’entrées audio et créer un son amélioré. Le modèle, explique l’équipe, permet aux utilisateurs d’ajuster des caractéristiques telles que le son des percussions, des accords de guitare ou même des mélodies pour créer un morceau. Le modèle peut également accepter la saisie de texte et l’utilisera pour donner du caractère à un morceau.
Un exemple serait de demander au modèle de générer un morceau de blues avec beaucoup de basse et de batterie. Cette opération serait ensuite suivie de descriptions similaires concernant d’autres instruments. L’équipe de Meta a également comparé JASCO à d’autres systèmes conçus pour faire à peu près la même chose et a constaté que JASCO les surpassait sur trois indicateurs majeurs.
AudioSeal peut être utilisé pour ajouter des filigranes à la parole générée par une application d’IA, ce qui permet d’identifier facilement les résultats comme étant générés artificiellement. Ils notent qu’il peut également être utilisé pour filigraner des segments de parole d’IA qui ont été ajoutés à une parole réelle et qu’il sera fourni avec une licence commerciale.
Les deux modèles Chameleon convertissent tous deux le texte en représentations visuelles et sont commercialisés avec des capacités limitées. Les versions 7B et 34B, note l’équipe, nécessitent toutes deux que les modèles acquièrent une certaine compréhension du texte et des images. De ce fait, ils peuvent effectuer un traitement inverse, comme la génération de légendes d’images.
Plus d’information:
Ou Tal et al, Conditionnement audio et symbolique conjoint pour la génération de texte en musique à contrôle temporel, arXiv (2024). DOI: 10.48550/arxiv.2406.10970
Page de démonstration : pages.cs.huji.ac.il/adiyoss-lab/JASCO/
arXiv
© 2024 Réseau Science X
Citation: Meta publie quatre nouveaux modèles d’IA accessibles au public pour l’utilisation des développeurs (3 juillet 2024) récupéré le 3 juillet 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.