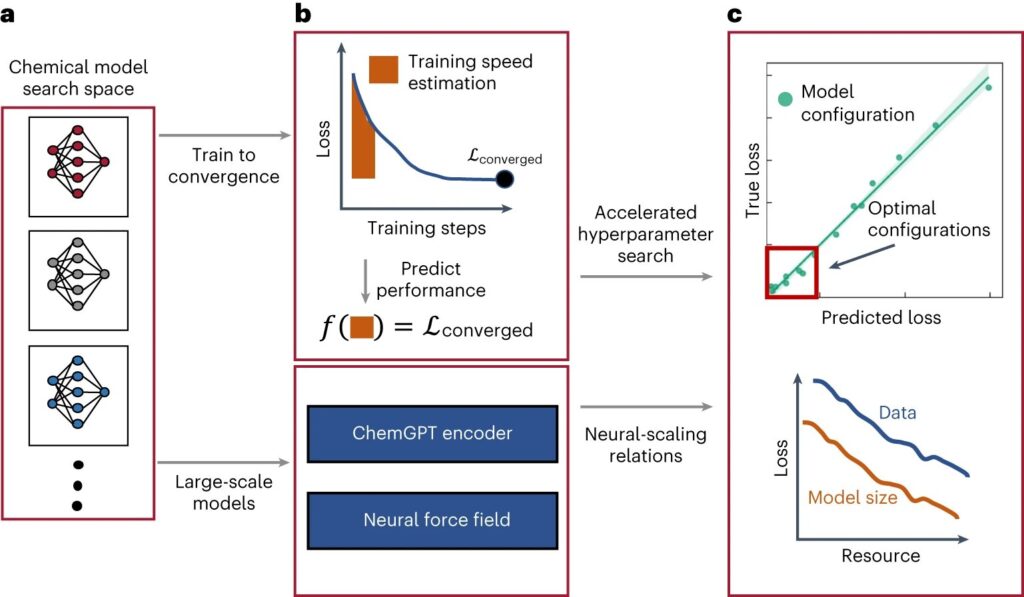
Découverte de relations à l’échelle neuronale pour les modèles chimiques profonds. un,bSur un domaine de candidats modèles (un), la perte finale et convergée du modèle n’est prévue qu’à partir de quelques époques initiales de formation pour les modèles à grande échelle (b). c, Les architectures de modèles non optimales et les configurations d’hyperparamètres sont identifiées dès le début de la formation, permettant une sélection efficace de l’architecture et des hyperparamètres idéaux. Le modèle doté des meilleurs hyperparamètres est ensuite entraîné avec différentes tailles de modèle et d’ensemble de données pour découvrir les relations à l’échelle neuronale. Crédit: Intelligence des machines naturelles (2023). DOI : 10.1038/s42256-023-00740-3
Les réseaux de neurones profonds (DNN) se sont révélés être des outils très prometteurs pour analyser de grandes quantités de données, ce qui pourrait accélérer la recherche dans divers domaines scientifiques. Par exemple, au cours des dernières années, certains informaticiens ont formé des modèles basés sur ces réseaux pour analyser les données chimiques et identifier les produits chimiques prometteurs pour diverses applications.
Des chercheurs du Massachusetts Institute of Technology (MIT) ont récemment mené une étude sur le comportement de mise à l’échelle neuronale de grands modèles basés sur DNN formés pour générer des compositions chimiques avantageuses et apprendre les potentiels interatomiques. Leur article, publié dans Intelligence des machines naturellesmontre à quelle vitesse les performances de ces modèles peuvent s’améliorer à mesure que leur taille et le pool de données sur lequel ils sont formés augmentent.
“L’article ‘Scaling Laws for Neural Language Models’ de Kaplan et al. a été la principale source d’inspiration de notre recherche”, a déclaré Nathan Frey, l’un des chercheurs qui ont mené l’étude, à Tech Xplore. “Cet article a montré que l’augmentation de la taille d’un réseau neuronal et de la quantité de données sur lesquelles il est formé conduit à des améliorations prévisibles dans la formation des modèles. Nous voulions voir comment la “mise à l’échelle neuronale” s’applique aux modèles formés à partir de données chimiques, pour des applications telles que la découverte de médicaments. “.
Frey et ses collègues ont commencé à travailler sur ce projet de recherche en 2021, donc avant la sortie des célèbres plateformes basées sur l’IA ChatGPT et Dall-E 2. À l’époque, la future mise à l’échelle des DNN était perçue comme particulièrement pertinente pour certains domaines et les études explorant leur mise à l’échelle dans les sciences physiques ou de la vie étaient rares.
L’étude des chercheurs explore la mise à l’échelle neuronale de deux types distincts de modèles pour l’analyse de données chimiques : un modèle de langage étendu (LLM) et un modèle basé sur un réseau neuronal graphique (GNN). Ces deux types différents de modèles peuvent être utilisés respectivement pour générer des compositions chimiques et apprendre les potentiels entre différents atomes dans des substances chimiques.
“Nous avons étudié deux types de modèles très différents : un modèle de langage autorégressif de type GPT que nous avons construit, appelé “ChemGPT”, et une famille de GNN”, a expliqué Frey. “ChemGPT a été formé de la même manière que ChatGPT, mais dans notre cas, ChemGPT essaie de prédire le prochain jeton d’une chaîne qui représente une molécule. Les GNN sont formés pour prédire l’énergie et les forces d’une molécule.”
Pour explorer l’évolutivité du modèle ChemGPT et des GNN, Frey et ses collègues ont exploré les effets de la taille d’un modèle et de la taille de l’ensemble de données utilisé pour l’entraîner sur diverses métriques pertinentes. Cela leur a permis de déterminer la vitesse à laquelle ces modèles s’améliorent à mesure qu’ils deviennent plus grands et reçoivent davantage de données.
“Nous trouvons un” comportement de mise à l’échelle neuronale “pour les modèles chimiques, qui rappelle le comportement de mise à l’échelle observé dans les modèles LLM et de vision pour diverses applications”, a déclaré Frey.
“Nous avons également montré que nous ne sommes pas proches d’une limite fondamentale pour la mise à l’échelle des modèles chimiques, il reste donc encore beaucoup de place pour approfondir les recherches avec davantage de calculs et des ensembles de données plus importants. L’incorporation de la physique dans les GNN via une propriété appelée “équivariance” a un effet positif. effet spectaculaire sur l’amélioration de l’efficacité de la mise à l’échelle, ce qui est un résultat passionnant car il est en réalité assez difficile de trouver des algorithmes qui modifient le comportement de mise à l’échelle. »
Dans l’ensemble, les résultats rassemblés par cette équipe de chercheurs jettent un nouvel éclairage sur le potentiel de deux types de modèles d’IA pour mener des recherches en chimie, montrant dans quelle mesure leurs performances peuvent s’améliorer à mesure qu’ils sont étendus. Ces travaux pourraient bientôt éclairer d’autres études explorant la promesse et la marge d’amélioration de ces modèles, ainsi que celles d’autres techniques basées sur le DNN pour des applications scientifiques spécifiques.
“Depuis la première apparition de nos travaux, des travaux de suivi passionnants ont déjà été réalisés pour sonder les capacités et les limites de la mise à l’échelle des modèles chimiques”, a ajouté Frey. “Plus récemment, j’ai également travaillé sur des modèles génératifs pour la conception de protéines et réfléchi à l’impact de la mise à l’échelle sur les modèles de données biologiques.”
Plus d’information:
Nathan C. Frey et al, Mise à l’échelle neuronale des modèles chimiques profonds, Intelligence des machines naturelles (2023). DOI : 10.1038/s42256-023-00740-3
© 2023 Réseau Science X
Citation: Une étude explore la mise à l’échelle des modèles d’apprentissage profond pour la recherche en chimie (11 novembre 2023) récupéré le 12 novembre 2023 sur
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.