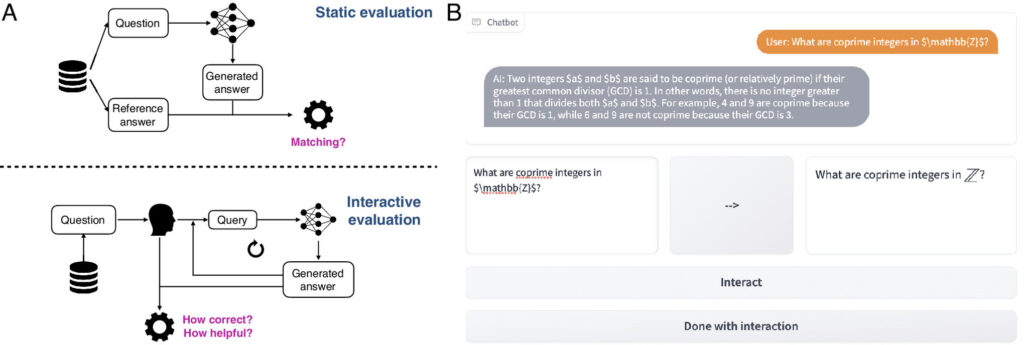
(A) Comparaison de l'évaluation statique typique (en haut) avec l'évaluation interactive (en bas), dans laquelle un humain interroge de manière itérative un modèle et évalue la qualité des réponses. (B) Exemple de sous-ensemble de l'interface de discussion de CheckMate où les utilisateurs interagissent avec un LLM. Le participant peut saisir sa requête (en bas à gauche), qui est compilée en LaTeX (en bas à droite). Lorsqu'il est prêt, le participant peut appuyer sur « Interagir » et faire acheminer sa requête vers le modèle. Crédit: Actes de l'Académie nationale des sciences (2024). DOI : 10.1073/pnas.2318124121
Une équipe d'informaticiens, d'ingénieurs, de mathématiciens et de spécialistes des sciences cognitives, dirigée par l'Université de Cambridge, a développé une plateforme d'évaluation open source appelée CheckMate, qui permet aux utilisateurs humains d'interagir avec et d'évaluer les performances de grands modèles de langage (LLM).
Les chercheurs ont testé CheckMate dans une expérience dans laquelle des participants humains utilisaient trois LLM – InstructGPT, ChatGPT et GPT-4 – comme assistants pour résoudre des problèmes de mathématiques de premier cycle.
L'équipe a étudié dans quelle mesure les LLM peuvent aider les participants à résoudre des problèmes. Malgré une corrélation généralement positive entre l'exactitude d'un chatbot et son utilité perçue, les chercheurs ont également trouvé des cas où les LLM étaient incorrects, mais néanmoins utiles pour les participants. Cependant, certains résultats incorrects du LLM ont été jugés corrects par les participants. Cela était particulièrement notable dans les LLM optimisés pour le chat.
Les chercheurs suggèrent des modèles qui communiquent l’incertitude, répondent bien aux corrections des utilisateurs et peuvent fournir une justification concise de leurs recommandations et constituent de meilleurs assistants. Les utilisateurs humains des LLM doivent vérifier soigneusement leurs résultats, compte tenu de leurs lacunes actuelles.
Les résultats, rapportés dans le Actes de l'Académie nationale des sciencespourrait être utile à la fois pour éclairer la formation à l’IA et pour aider les développeurs à améliorer les LLM pour un plus large éventail d’utilisations.
Si les LLM deviennent de plus en plus puissants, ils peuvent également commettre des erreurs et fournir des informations incorrectes, ce qui pourrait avoir des conséquences négatives à mesure que ces systèmes s'intègrent davantage dans notre vie quotidienne.
“Les LLM sont devenus très populaires et il est important d'évaluer leurs performances de manière quantitative, mais nous devons également évaluer dans quelle mesure ces systèmes fonctionnent avec les gens et peuvent les aider”, a déclaré le co-premier auteur Albert Jiang, du département d'informatique de Cambridge. et la technologie. “Nous ne disposons pas encore de moyens complets pour évaluer les performances d'un LLM lorsqu'il interagit avec des humains.”
La méthode standard d'évaluation des LLM repose sur des paires statiques d'entrées et de sorties, ce qui ne tient pas compte de la nature interactive des chatbots et de la manière dont cela modifie leur utilité dans différents scénarios. Les chercheurs ont développé CheckMate pour aider à répondre à ces questions, conçu pour, sans toutefois s'y limiter, les applications en mathématiques.
“Lorsqu'ils parlent aux mathématiciens des LLM, beaucoup d'entre eux se répartissent dans l'un des deux camps principaux : soit ils pensent que les LLM peuvent produire des preuves mathématiques complexes par eux-mêmes, soit que les LLM sont incapables de faire de l'arithmétique simple”, a déclaré la co-première auteure Katie Collins. du Département d'ingénierie. “Bien sûr, la vérité se situe probablement quelque part entre les deux, mais nous voulions trouver un moyen d'évaluer pour quelles tâches les LLM conviennent et lesquelles ne le sont pas.”
Les chercheurs ont recruté 25 mathématiciens, des étudiants de premier cycle aux professeurs seniors, pour interagir avec trois LLM différents (InstructGPT, ChatGPT et GPT-4) et évaluer leurs performances à l'aide de CheckMate. Les participants ont travaillé sur des théorèmes mathématiques de premier cycle avec l'aide d'un LLM et ont été invités à évaluer chaque réponse individuelle du LLM pour son exactitude et son utilité. Les participants ne savaient pas avec quel LLM ils interagissaient.
Les chercheurs ont enregistré les types de questions posées par les participants, la façon dont les participants ont réagi lorsqu'on leur a présenté une réponse totalement ou partiellement incorrecte, s'ils ont tenté de corriger le LLM et comment, ou s'ils ont demandé des éclaircissements. Les participants avaient différents niveaux d'expérience dans la rédaction d'invites efficaces pour les LLM, ce qui affectait souvent la qualité des réponses fournies par les LLM.
Un exemple d'invite efficace est « quelle est la définition de X » (X étant un concept dans le problème), car les chatbots peuvent être très efficaces pour récupérer les concepts qu'ils connaissent et les expliquer à l'utilisateur.
“L'une des choses que nous avons découvertes est la faillibilité surprenante de ces modèles”, a déclaré Collins. “Parfois, ces LLM seront très bons en mathématiques de niveau supérieur, puis ils échoueront dans quelque chose de beaucoup plus simple. Cela montre qu'il est essentiel de réfléchir attentivement à la manière d'utiliser les LLM de manière efficace et appropriée.”
Cependant, comme pour les LLM, les participants humains ont également commis des erreurs. Les chercheurs ont demandé aux participants d'évaluer leur degré de confiance en leur propre capacité à résoudre le problème pour lequel ils utilisaient le LLM. Dans les cas où les participants avaient moins confiance en leurs propres capacités, ils étaient plus susceptibles de considérer comme correctes les générations incorrectes par LLM.
“Cela pose un grand défi dans l'évaluation des LLM, car ils deviennent si doués pour générer un langage naturel agréable et apparemment correct qu'il est facile de se laisser berner par leurs réponses”, a déclaré Jiang. “Cela montre également que même si l'évaluation humaine est utile et importante, elle est nuancée et parfois erronée. Toute personne utilisant un LLM, pour n'importe quelle application, doit toujours prêter attention au résultat et le vérifier lui-même.”
Sur la base des résultats de CheckMate, les chercheurs affirment que les nouvelles générations de LLM sont de plus en plus capables de collaborer utilement et correctement avec des utilisateurs humains sur des problèmes mathématiques de premier cycle, à condition que l'utilisateur puisse évaluer l'exactitude des réponses générées par le LLM.
Même si les réponses peuvent être mémorisées et trouvées quelque part sur Internet, les LLM ont l'avantage d'être flexibles dans leurs entrées et sorties par rapport aux moteurs de recherche traditionnels (bien qu'ils ne devraient pas remplacer les moteurs de recherche dans leur forme actuelle).
Si CheckMate a été testé sur des problèmes mathématiques, les chercheurs affirment que leur plateforme pourrait être adaptée à un large éventail de domaines. À l'avenir, ce type de retour d'information pourrait être incorporé dans les LLM eux-mêmes, bien qu'aucun retour d'information CheckMate de l'étude actuelle n'ait été réinjecté dans les modèles.
“Ces types d'outils peuvent aider la communauté des chercheurs à mieux comprendre les forces et les faiblesses de ces modèles”, a déclaré Collins. “Nous ne les utiliserions pas comme outils pour résoudre seuls des problèmes mathématiques complexes, mais ils peuvent être des assistants utiles si les utilisateurs savent comment en tirer parti.”
Plus d'information:
Katherine M. Collins et al, Évaluation des modèles de langage pour les mathématiques par le biais d'interactions, Actes de l'Académie nationale des sciences (2024). DOI : 10.1073/pnas.2318124121
Fourni par l'Université de Cambridge
Citation: Une nouvelle plate-forme open source permet aux utilisateurs d'évaluer les performances des chatbots basés sur l'IA (4 juin 2024) récupéré le 4 juin 2024 sur
Ce document est soumis au droit d'auteur. En dehors de toute utilisation équitable à des fins d'étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.